软件学习的「全局认识」
学习软件时,只有理解了软件的设计原理,及其背后的高阶模型,才能更好的反向利用。例如主动创造锚点方便高级搜索,主动完善、积累元数据,分类方式等。
反之,在一堆教程中积累小技巧,做单纯的积累工作。不从软件底层出发学习,动用自己的检索能力,尽可能击中 Zotero 大多数功能与技巧。你就难以发挥 Zotero 的全部威力。
对一个软件,其实,只要把它的说明书抽样阅读一边,跟着时间线看完版本历史记录以及补丁维护系统,大部分问题就不存在了。而这是习得软件最重要的 80%,不要把时间浪费在小技巧上,积累那 20%。
如果学习 Zotero 没发现其用上元数据、底层协议等,那么都是买椟还珠。比如,有没有意识到意识到 Zotero 默认协议,其实就是通用的信息协议?Collection 的分类模版是基于本体论,再利用认知心理学的,7 加减 2 法则,重构,合并同类项出来的?
思考角度,个人推荐,从开发者和使用者的两个角度分析。
- 开发者角度:可以分析 Zotero 是如何在导入信息的阶段、信息输出的阶段(反向利用)利用协议和元数据。亦或者将其用于本身软件中信息的交换。
- 使用者角度:而我们,Zotero 的使用者,又如何反向利用底层协议,和元数据呢?辅助我们信息分析?
Zotero 中的底层协议
Zotero 默认的协议是 Bibliographic Ontology。它是定义信息世界的协议,包括了实体信息的载体,如图书、打印出来的论文;也包括了虚拟信息的载体:软件、聊天记录等等。在 Zotero 中无论是 Paper、Book、Film 等实体…..都用 Bibliographic Ontology 协议抽象统称为一个最小的基本单位 Item。然后再对这个实体进行调用,创建,修改等操作……
Zotero 把信息处理的过程抽象为对 Item 的四个操作:CRUD。
- C - 创造实体(Create)
- R - 读取实体(Retrieve)
- U - 更新实体(Update)
- D - 删除实体(Delete)
在构建每个步骤时,Zotero 通过寻找相应模块已有的行业标准协议或创建新行业标准协议。而且用户可以根据不同模块相应的协议,按照一定的模式和规则,不断地添加具体的实例,从而展现了极强的可供性。例如在创造实体时使用本体论相关协议。在读取实体时,Zotero 设计了 CSL、Translators 等工具供用户使用。删除多余实体时,提供 Duplicate Items 快速合并功能……
这里就不得不提到 Zotero 两个超级伟大的发明:Translators 和 CSL。
Translators 是编写好的 js 脚本,用于识别不同类型的网站、文献库中的元数据,并批量添加到 Zotero 中进行管理。使用 Translators 坦然地面对不同的信息类型,从最常见的论文,书籍,到冷门的音乐,GitHub 代码库,都可用 Translators 抓取。
CSL 全称 Citation Style Language,引文风格语言。在 Zotero 提供的 Zotero style repository 中有 9201 种引文的款式,包含了各种学科。随便点击一个就可以下载。这个网站链接了 CSL 官网,惊讶发现 Zotero 是 CSL 的赞助商之一。并且有很多其他软件也使用了这个 CSL 底层协议。PS:优秀的软件对底层协议的支持不会差,你也可以顺藤摸瓜看看还有哪些软件是基于底层协议设计的。这也和一般知识管理软件先了解用户的需求出发自下而上设计略有不同。
CSL 让你在输出信息时坦然面对不同期刊的引文要求。
所以 Zotero 其实是一个基于本体论的自动化的利用底层协议处理元数据的开源软件。通过少量的信息从高维角度描述信息,帮助全局认识的形成,这也是别的知识管理软件做不到的。
能如何利用底层协议?
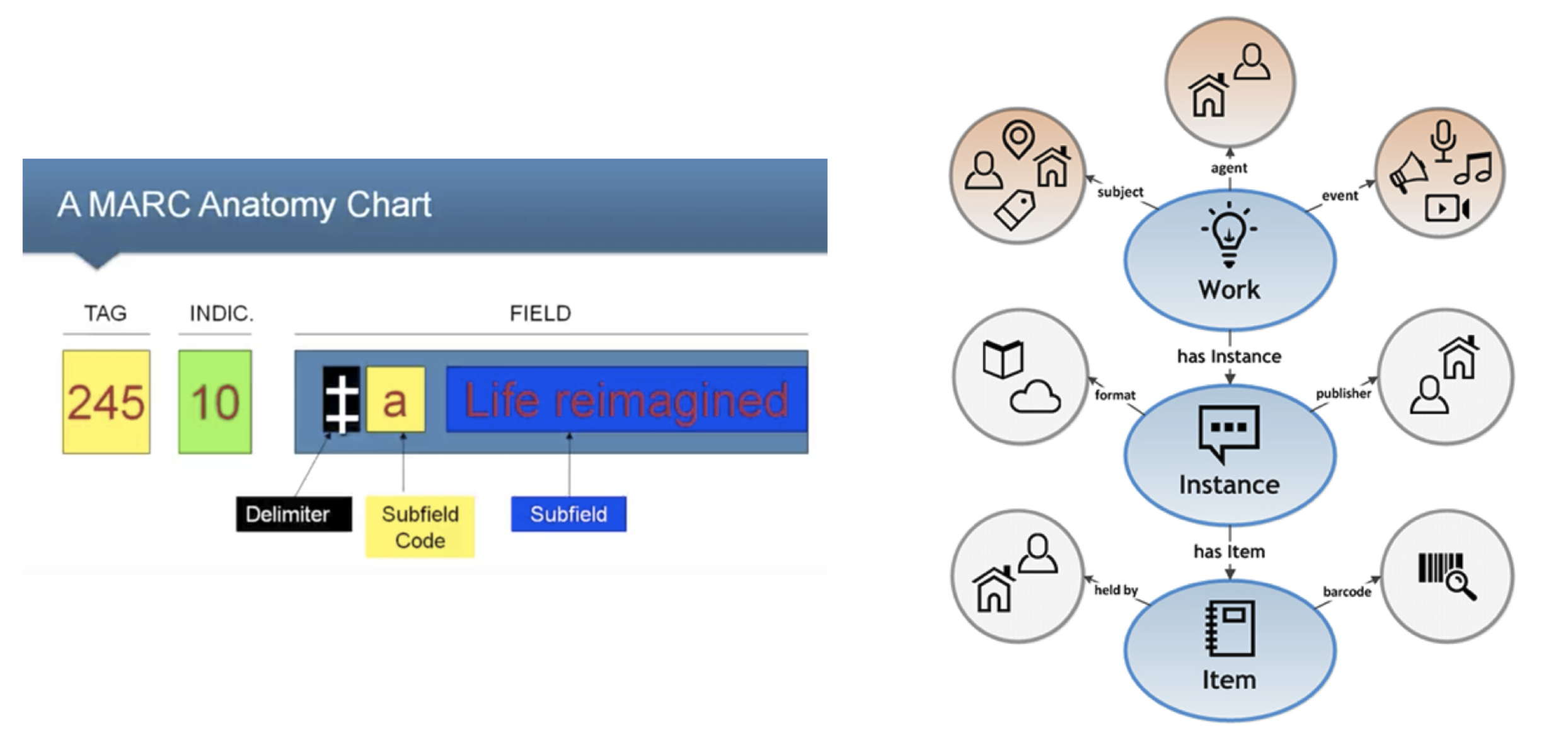
Zotero 的 Bibliographic Ontology 与 MARC (Machine Readable Cataloging) 协议带给我们的启发是,一旦你掌握了的本质,即家谱网站和图书网站共同的底层协议 MARC,就可以通过协议再反向去推论优质的资讯和优质资源。比如寻找最佳的知识管理软件,看看它是否兼容这些协议,就可以对这个软件的品质有一个判断。这样的思路就能站在一个更高维的一个角度,用最小的时间,最小的成本获取领域中的关键信息。
利用 Translators 反向寻找优质资源——开源社区贡献了 400+ 种 Translators,用以抓取世界上主要的优质信息资讯网站信息。掌握这个清单,相当于用最小的成本比如 20% 的力气,获取了全球最优质资源的 80%。你可以在本地 Translators 寻找有什么优质信息源是我不知道的?
学习软件一些「实践策略」
形成了对 Zotero 的全局认识后就高枕无忧了吗?障碍才刚刚开始。
你会遇到的第一个障碍是习惯养成前的「行动瘫痪」。在大脑意识到怎么操作,肉体还没跟上时,是最容易行动瘫痪的。就算学会了 Zotero 的认识,也知道行动方向也会行动瘫痪。
你需要强迫自己坚持到这些技巧成为你的肌肉记忆(大约需要 21 天)。同样,一个高效的精心设计的工作流不见得能快速上手(可能流程复杂),需要时间适应复杂流程。你需要的是一个,能坚持下来的,符合最小成本原则,符合人脑工作规律的工作流。
第二个障碍可能是「遇见无法解决的软件技术问题」。就算把说明书,版本记录看完,也解决不了,这时候可以用检索式 site:forums.zotero.org。
第三个障碍是「不清楚怎么设计软件工作流」。我个人并不推荐看特别多的实例,大概率是无法解决的。可以主动联系网上一些教程作者,咨询解决问题的人。
尾声
Zotero 是创造者的工具,既然是创造者的工具,创造者的积极性和主动性是毋庸置疑和必须具备的。好的工具内隐了大量专家模式与高阶模型。
试图构最小全局认识,不断提出问题是领悟 Zotero 的捷径。但真正的经验大多都来自不断的实践与切身体会。围绕核心,选择工具、练习实践,最后融入现有工作流。
工具的学习是要实践的,不能像仓鼠,不停囤积工具等待寒冬来临。而应该在不同情境中反复刻意练习,直至成为本能反应,真正内隐所学。多尝试新工具,例如配置高级搜索,折腾插件。也可参考 Learn Python the hard way 的思路,多创造几次练手机会,多压力测试,例如在学术里就有很多 Zotero 的实践,使用 Zotero 批量筛选并阅读论文,相信大家尝试过后就会有点感觉了。
Zotero 对与知识创造的价值建立在大时间周期上的坚持,那些看似微不足道,细节的实践策略,帮助可不小。过了一段时间,可以自问,看到优质文献,优质信息,有没有保存到 Zotero 上的习惯?探索一个新领域,会不会快速调整 Collection 树型结构并批量抓取领域硕博论文……
认知过程无法一步到位,只能一层一层深化的,随着随着知识储备的增加,对信息管理理解日益深刻,逐步从新手,达到专业、高手、大师水准。
ChangeLog
- 190310 init